Apache Spark
Apache Spark
- Apache Spark is a framework for real time data analytics in a distributed computing environment.
- The Spark is written in Scala and was originally developed at the University of California, Berkeley.
- It executes in-memory computations to increase speed of data processing over Map-Reduce.
- It is 100x faster than Hadoop for large scale data processing by exploiting in-memory computations and other optimizations. Therefore, it requires high processing power than Map-Reduce.
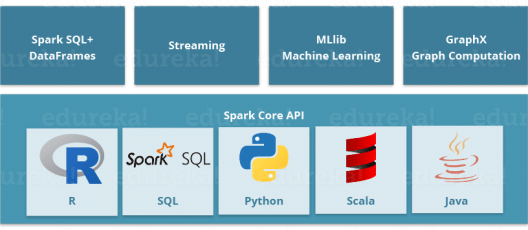
As you can see, Spark comes packed with high-level libraries, including support for R, SQL, Python, Scala, Java etc. These standard libraries increase the seamless integrations in complex workflow. Over this, it also allows various sets of services to integrate with it like MLlib, GraphX, SQL + Data Frames, Streaming services etc. to increase its capabilities.
This is a very common question in everyone’s mind:
“Apache Spark: A Killer or Saviour of Apache Hadoop?” – O’Reily
The Answer to this – This is not an apple to apple comparison. Apache Spark best fits for real time processing, whereas Hadoop was designed to store unstructured data and execute batch processing over it. When we combine, Apache Spark’s ability, i.e. high processing speed, advance analytics and multiple integration support with Hadoop’s low cost operation on commodity hardware, it gives the best results.
That is the reason why, Spark and Hadoop are used together by many companies for processing and analyzing their Big Data stored in HDFS.


Comments
Post a Comment